
公开数据集

 数据结构 ?
1.98G
数据结构 ?
1.98G
 Data Structure ?
Data Structure ?

* 以上分析是由系统提取分析形成的结果,具体实际数据为准。
README.md
With nearly one billion online videos viewed everyday, an emerging new frontier in computer vision research is recognition and search in video. While much effort has been devoted to the collection and annotation of large scalable static image datasets containing thousands of image categories, human action datasets lack far behind. Here we introduce HMDB collected from various sources, mostly from movies, and a small proportion from public databases such as the Prelinger archive, YouTube and Google videos. The dataset contains 6849 clips divided into 51 action categories, each containing a minimum of 101 clips. The actions categories can be grouped in five types:
General facial actions smile, laugh, chew, talk.
Facial actions with object manipulation: smoke, eat, drink.
General body movements: cartwheel, clap hands, climb, climb stairs, dive, fall on the floor, backhand flip, handstand, jump, pull up, push up, run, sit down, sit up, somersault, stand up, turn, walk, wave.
Body movements with object interaction: brush hair, catch, draw sword, dribble, golf, hit something, kick ball, pick, pour, push something, ride bike, ride horse, shoot ball, shoot bow, shoot gun, swing baseball bat, sword exercise, throw.
Body movements for human interaction: fencing, hug, kick someone, kiss, punch, shake hands, sword fight.
Citation
The benchmark and database are described in the following article. We request that authors cite this paper in publications describing work carried out with this system and/or the video database.
H. Kuehne, H. Jhuang, E. Garrote, T. Poggio, and T. Serre. HMDB: A Large Video Database for Human Motion Recognition. ICCV, 2011.PDF Bibtex
The first benchmark STIP features are described in the following paper and we request the authors cite this paper if they use STIP features.
I. Laptev, M. Marszalek, C. Schmid, and B. Rozenfeld. Learning Realistic Human Actions From Movies. CVPR, 2008. PDF
The second benchmark C2 features are described in the following paper and we request the authors cite this paper if they use C2 codes.
H. Jhuang, T. Serre, L. Wolf, and T. Poggio. A Biologically Inspired System for Action Recognition. ICCV, 2007. PDF
Dataset, meta labels, statistics and stabilization
meta labels
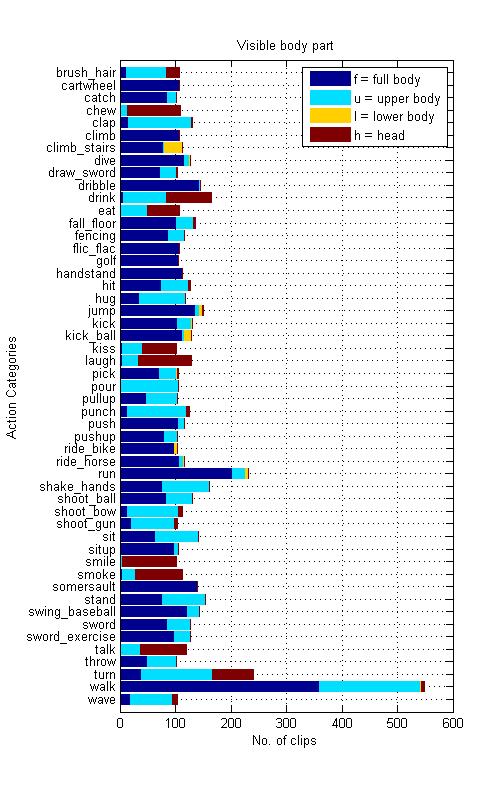
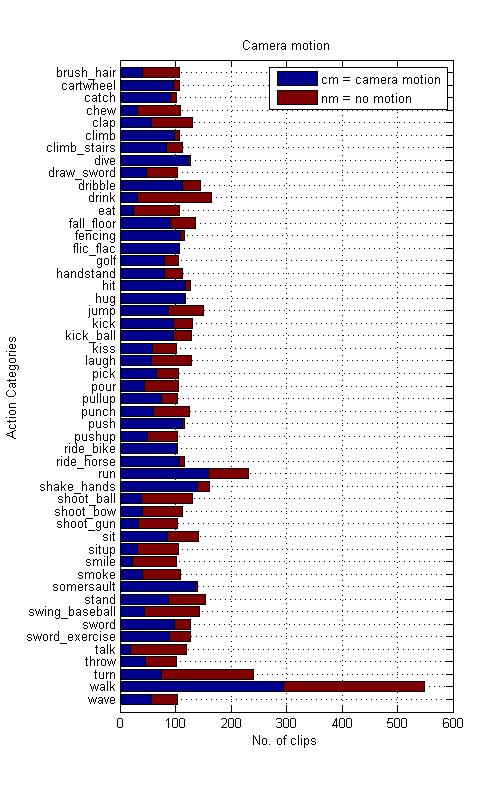
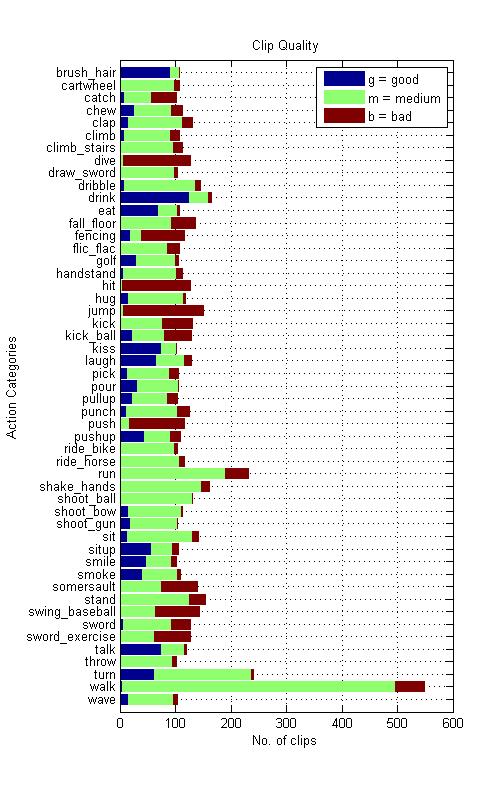
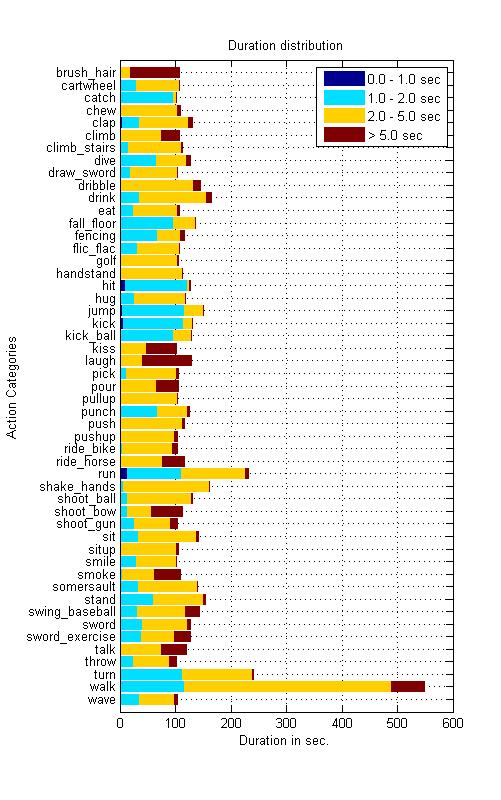
In addition to the label of the action category, each clip is annotated with an action label as well as a meta-label describing the property of the clip. Because HMDB51 video sequences are extracted from commercial movies as well as YouTube, it represents a fine multifariousness of light conditions, situations and surroundings in which the action can appear, captured with different camera types and recording techniques such as points of view. The point of view is another criterion of subdivision the HMDB supports. For an all-around coverage the perspectives frontal, lateral (right and left) and backwards view of motions are distinguishable. In addition we have two distinct categories namely “no motion” and “camera motion”. The later is the result of zooming, traveling shots and camera shaking, etc. A 3 level grading of video quality is applied to evaluate the large set of clips. only those video samples are rated “good” which have the quality that you can identify the single fingers during the motion. Those which do not meet this requirement are either rated “medium” or “bad” if body parts or limbs vanish while the action is executed. Below you can find examples for each of the grades to show the differences.
| Property | Labels (abbreviation) |
|---|---|
| visible body parts | head(h), upper body(u), full body (f), lower body(l) |
| camera motion | motion (cm), static (nm) |
| camera viewpoint | Front (fr), back (ba), left(le), right(ri) |
| number of people involved in the action | Single (np1), two (np2), three (np3) |
| video quality | good (goo), medium (med), ok (bad) |
Statistics

Video Stabilization
One major challenge associated with the use of video clips extracted from real-world videos is the potential presence of significant camera/background motion, which is assumed to interfere with the local motion computation and should be corrected. To remove the camera motion, we used standard image stitching techniques to align frames of a clip. These techniques estimate a background plane by detecting then matching salient features in two adjacent frames. Correspondences of two frames are computed using a distance measure that includes both the absolute pixel differences and the Euler distance of the detected points. Points with a minimum distance are then matched and the RANSAC algorithm is used to estimate the geometric transformation between all neighbor- ing frames (independently for every pair of frames). Using this estimate, the single frames are warped and combined to achieve a stabilized clip.
Other action recognition benchmark
The effort was initiated at KTH: the KTH Dataset contains six types of actions and 100 clips per action category. It was followed by the Weizmann Dataset collected at the Weizmann Institute, which contains ten action categories and nine clips per category. Above two sets were recorded in controlled and simplified settings. Then the first realistic-action dataset collected from movies and annotated from movie scripts is made in INRIA; the Hollywood Human Actions Set contains 8 types of actions, and the number of clips per action class varies between 60 – 140 per class. Its extended version, Hollywood2 Human Actions Set offers a total of 3669 videos distributed over ten classes of human actions under ten types of scenarios. The UCF group has also been collecting action datasets, mostly from YouTube. There are UCF Sports featuring 9 types of sports and a total of 182 clips, UCF YouTube containing 11 action classes, and UCF50 contains 50 actions classes. We will show in the paper that videos from YouTube could be very biased by low-level features, meaning low-level features (i.e., color and gist) are more discriminative than mid-level fears (i.e., motion and shape).
| Dataset | Year | # Actions | # Clips per Action |
|---|---|---|---|
| KTH | 2004 | 6 | 10 |
| Weizmann | 2005 | 9 | 9 |
| IXMAS | 2006 | 11 | 33 |
| Hollywood | 2008 | 8 | 30-140 |
| UCF Sports | 2009 | 9 | 14-35 |
| Hollywood2 | 2009 | 12 | 61-278 |
| UCF YouTube | 2009 | 11 | 100 |
| MSR | 2009 | 3 | 14-25 |
| Olympic | 2010 | 16 | 50 |
| UCF50 | 2010 | 50 | min. 100 |
| HMDB51 | 2011 | 51 | min. 101 |
Contact
For questions about the datasets and benchmarks, please contact Hueihan Jhuang ( hueihan.jhuang [at] tuebingen.mpg.de).


- 分享你的想法
全部内容
数据使用声明:
- 1、该数据来自于互联网数据采集或服务商的提供,本平台为用户提供数据集的展示与浏览。
- 2、本平台仅作为数据集的基本信息展示、包括但不限于图像、文本、视频、音频等文件类型。
- 3、数据集基本信息来自数据原地址或数据提供方提供的信息,如数据集描述中有描述差异,请以数据原地址或服务商原地址为准。
- 1、本站中的所有数据集的版权都归属于原数据发布者或数据提供方所有。
- 1、如您需要转载本站数据,请保留原数据地址及相关版权声明。
- 1、如本站中的部分数据涉及侵权展示,请及时联系本站,我们会安排进行数据下线。
 VIP下载(最低0.24/天)
VIP下载(最低0.24/天) 2708浏览
2708浏览 23下载
23下载 2点赞
2点赞 收藏
收藏 分享
分享