
公开数据集
 数据结构 ?
80T
数据结构 ?
80T
 Data Structure ?
Data Structure ?

* 以上分析是由系统提取分析形成的结果,具体实际数据为准。
README.md
一、LAION-5B概述
LAION-5B由58.5亿个图像文本组合组成,通过CLIP过滤的图像分类模型,其中23亿是图像-英文文本对,22亿是图像,超过100个是非英语文本对,其余10亿对是不限于特定语言的图像和文本对,例如名称。在发布时发表的一份声明中,LAION研究团队表示,虽然在数十亿个图像文本对上训练的大规模图像文本模型显示出高性能,但这种规模的训练数据集通常不可用。
在创建图像和文本对时,LAION 会分析在 Internet 上提供数据的Common Crawl文件,选择文本和图像对,并使用 CLIP 创建高度相似的图像和文本对,提取数据。此外,尽可能删除太短的文本、分辨率过高的图像、重复数据、非法内容等,最终保留了由 58.5 亿个图像和文本对组成的样本。
LAION-5B通过CommonCrawl获取文本和图片,OpenAI的CLIP计算后获取图像和文本的相似性,并删除相似度低于设定阈值的图文对(英文阈值0.28,其余阈值0.26),500亿图片保留了不到60亿,最后形成58.5亿个图文对,包括23.2亿的英语,22.6亿的100+语言及12.7亿的未知语言。
LAION-5B的数据规模目前最大,可以对许多未公开的多模态模型进行训练并获得较好效果,并公开了第一个开源的CLIP模型。并且数据多样,包含各种领域图片,对于后续研究提供了更多的方向,比如数据重叠、图片噪声、不适图片筛选、低资源语言、自然语言对于多模态的作用、模型偏差等等。
但如果将LAION-5B直接应用于工业,需要注意清洗图片,因为LAION-5B中含水印图片及不适图片,模型会因此产生偏差。
二、LAION-5B数据组成:
1、laion2B-en:包含23.2亿条中有英文文本

2、laion2B-multi :22.6亿包含来自100多种其他语言的文本

3、laion1B-nolang:12.7亿的文本中无法清楚地检测到特定的语言

三、LAION可以做什么任务
LAION提供了大规模的图文数据,可以用来做大部分多模态及CV工作,多模态方面包括大规模预训练、图文匹配、图像生成(图像生成、图像修复/编辑等)和文本生成(图像生成文本、VQA等)等下游任务,CV方面包含分类等,LAION也提供了使用数据集训练的模型作为参考。
3.1 图文匹配及多模态预训练
包括但不限于任务:多模态预训练、图文匹配、图文检索。
CLIP模型使用对比学习将图像和文本嵌入到相同空间,标志着图像-文本的多模态的进展,用于图文匹配/检索、zero-shot分类等领域。但CLIP并未公开训练数据,因此LAION分别使用LAION-400M和LAION-2B重新训练了CLIP模型,准确率和OpenAI版本不相上下。
3.2 生成任务
● 图像生成
包括但不限于任务:高分辨率图像生成、图像修复/编辑、文本生成图片、条件图像生成。
LAION提供了子集来过滤不适图片和水印图片,为图像生成进一步提供了条件。目前有不少模型可以基于LAION子集来生成,DALLE这种自回归模型或者GLIDE这种扩散模型,以下给出几个例子:
- Stable Diffusion使用LAION-5B的子集,在压缩的空间对图像进行重建,可生成百万像素的高分辨率图片,用于图像修复、图像生成等。
- VQ-Diffusion模型使用矢量量化变异自动编码器,在LAION-400M训练文本生成图像的模型,获得更高的图像质量。
- Imagen[15]在LAION-400M的子集上训练,使用强大的语言模型抽取特征,并指导生成对应文本的高质量图像,击败DALLE-2[20]实现SOTA。
- 也可以挑选其中领域图片进行生成,如人脸生成FARL。
● 文本生成
包括但不限于任务:图像生成文本、VQA、Visual Entailment
- BLIP重新在LAION-400M中115M子集上训练,再使用CLIP对候选描述排序,评测后优于其他模型,用于描述生成和图文匹配。
- MAGMA[19]在LAION子集上训练,基于适配器的微调来增强语言模型的生成,为视觉问题生成答案,仅使用simVLM的0.2%的数据量但生成了较好的结果。
3.3 分类任务
可以做zero-shot、finetune和训练。
通过web搜索子集或官方提供的子集,可以做构建分类识别,水印识别、色情内容识别、面部特征学习等等。也可以通过提供的大规模预训练模型,在下游任务做zero-shot和finetune。
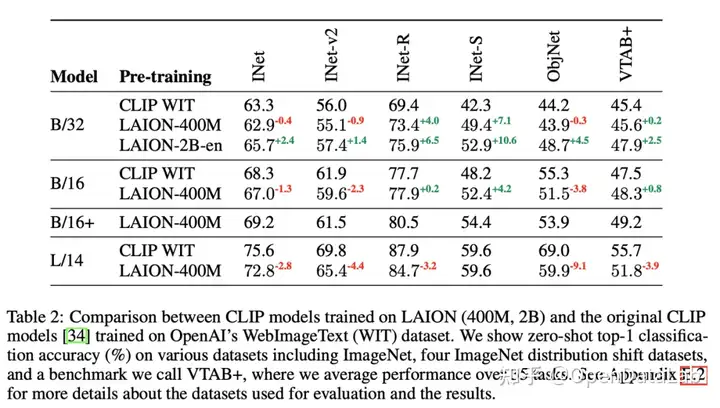
图5: 对比了WIT(官方)、在LAION-400M和LAION-2B-en上训练的CLIP模型在下游数据集的zero-shot性能对比,可以看到LAION训练的模型性能优越。
3.4 其他任务
LAION数据丰富,可以筛选需要的数据做其他任务,比如可以在LAION-2B-multi中筛选指定语言数据做低资源语言任务,可以做数据重叠对模型的影响、模型偏见等等。
四、如何使用LAION
对于有丰富GPU资源的同学,在训练任务时,可以使用全集/子集数据进行大规模训练。对于资源相对有限的同学,无法进行大规模训练,依然可以使用LAION预训练模型进行zero-shot、finetune等研究,也可以将其作为图像资源池自行检索所需图像。
4.1 大规模训练
可以使用全集/子集来训练,完成多模态、视觉领域相关任务,往往对资源需求较大。
● 全集为58.5亿图文对,通过CLIP过滤,含有少量噪声和不适数据。
● 子集参考2.1中提供的多种子集,包括但不限于无不适图片子集、无水印子集、超分辨率子集、美学子集等等。
● 如果没有合适的子集,也可以通过web检索页面,到合适的数据下载,可以生成图像子集进行训练,也可以选择适合训练的图像分辨率,该方法的好处是可以根据自定义场景选择图片。
4.2 少量训练
对于资源有限的工程师,可以选择LAION-5B中所需数据和LAION-5B提供的预训练模型,进行训练。
● 数据方面
可以选取LAION-5B的部分数据进行训练,比如通过web检索界面检索自定义场景图片,或者使用有/无水印图片、高分辨率图片、美学分数较高图片等等,进行小规模训练。
● 模型方面
可以使用LAION提供的预训练模型对下游进行zero-shot、few-shot或finetune。
- zero-shot/few-shot:官方提供了大规模预训练的开源模型,CLIP、BLIP等,效果显著,基于LAION训练的CLIP性能与原模型不相上下。基于LAION-400M训练的CLIP性能可以参考图6。
- finetune:官方提供了微调方式供参考:https://github.com/mlfoundations/wise-ft,也可以采取常规的finetune方式进行训练。
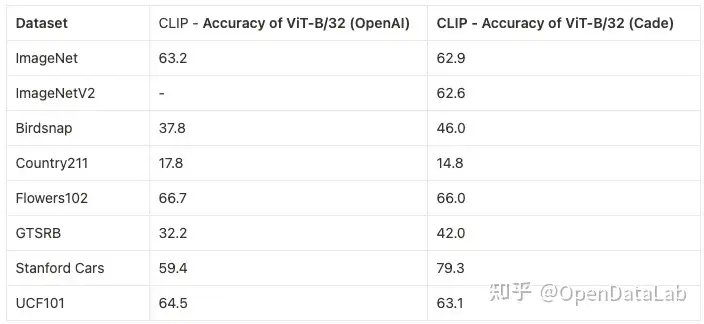
图6: CLIP基于LAION-400M对ImageNet、ImageNetV2、Birdsnap、Country211、Flowers102、GTSRB、Standford Cars、UCR101等数据集进行测试,和OpenAI的CLIP性能不相上下。数据来源:https://github.com/mlfoundations/open_clip


- 分享你的想法
全部内容
数据使用声明:
- 1、该数据来自于互联网数据采集或服务商的提供,本平台为用户提供数据集的展示与浏览。
- 2、本平台仅作为数据集的基本信息展示、包括但不限于图像、文本、视频、音频等文件类型。
- 3、数据集基本信息来自数据原地址或数据提供方提供的信息,如数据集描述中有描述差异,请以数据原地址或服务商原地址为准。
- 1、本站中的所有数据集的版权都归属于原数据发布者或数据提供方所有。
- 1、如您需要转载本站数据,请保留原数据地址及相关版权声明。
- 1、如本站中的部分数据涉及侵权展示,请及时联系本站,我们会安排进行数据下线。
 VIP下载(最低0.24/天)
VIP下载(最低0.24/天) 4485浏览
4485浏览 33下载
33下载 1点赞
1点赞 收藏
收藏 分享
分享