
46.5M
782
5
斯坦福情感树银行v2(SST2)
Arts and Entertainment,Education,Movies and TV Shows,NLP,Text Data
Classification
![]() 前往PC端下载数据
前往PC端下载数据
Context **`Stanford Sentiment Treebank V1.0`** `Live Demo :` http://nlp.stanford.edu:8080/sentiment/rntnDemo.html 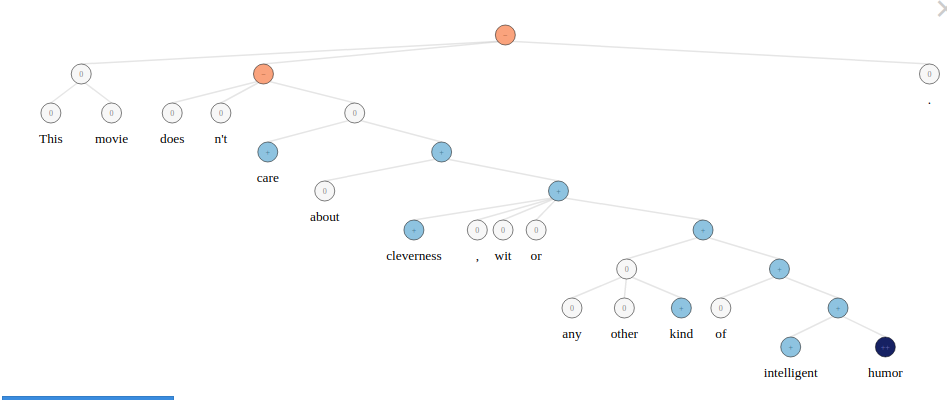 This is the dataset of the paper: **Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank** Richard Socher, Alex Perelygin, Jean Wu, Jason Chuang, Christopher Manning, Andrew Ng and Christopher Potts Conference on Empirical Methods in Natural Language Processing (EMNLP 2013) Content 11,855 sentences from movie reviews Parses generated using Stanford parser Treebank generated from parses 215,154 unique phrases Phrases annotated by Mechanical Turk for sentiment What's inside is more than just rows and columns. Make it easy for others to get started by describing how you acquired the data and what time period it represents, too. Acknowledgements If you use this dataset in your research, please cite the above paper. > @incollection{SocherEtAl2013:RNTN, > title = {{Parsing With Compositional Vector Grammars}}, > author = {Richard Socher and Alex Perelygin and Jean Wu and Jason Chuang and Christopher Manning and Andrew Ng and Christopher Potts}, > booktitle = {{EMNLP}}, > year = {2013} > } `Additional Source of Dataset`: https://github.com/clairett/pytorch-sentiment-classification/tree/master/data/SST2 Inspiration Transformers have been a flashy topic in AI world, good enough to bring anyone's attention. People want to explore about these models and may be they end up with some MAGIC better than these models. Keeping this in mind, I have uploaded this dataset here, to ease people understand the data, Read the research paper, included. and; try their own approaches on getting a kick from my starter kernel.
版权信息
- 数据大小46.5M
- 发布者Atul Anand {Jha}
- 引用地址
- 许可协议CC0: Public Domain